How to get started with Reinforcement Learning (RL)

This blog is the last one in my series of “deep learning update” blogs, where I was sharing my learnings as I was intensively researching various ML/deep learning subfields over the last 16 months.
Aside from sharing my learnings, the idea of these blogs is to give you the general learning-how-to-learn tips & tricks, which I’ve built up over the last many years of self-study that started way before “my AI story” was even a thing, as well as the specific advice peculiar to a particular subfield which I’m currently working on. And as they say:
To help others you only need to be one step ahead. — some{one, when, where}
The goal of these blogs is to get you started really fast so that you can build up solid foundations in the ML/deep learning subfield X, where so far this variable X = {Computer Vision (CV), NLP, Graph ML, RL}.
Now, you may ask yourself (but probably not 😂), why do I make these? Well, there are, as always, multiple reasons. The main ones I can think of are:
- I genuinely love helping others and hearing from you. All the feedback I get from you fuels me even more.
- I wished there was a blog post like this one when I started learning each of these AI subfields, that structured the knowledge of the field in a way that’s as linear as possible guiding me through the ocean 🌊 of information (or is it a graph of information? 😜 (with cycles of course!)).
- Future me will be grateful as well — in case I need to quickly overview a particular topic again.
- Writing blogs helps me further consolidate my knowledge and crystalize my thoughts — I can’t recommend it enough! Start writing your own blog.
In this one, I’ll give you some tips on how to get started with RL, but before that, as usual, let me give you a super short review of my previous content if you’re new here!
Blogs 📚
Here are some of my previous blogs 📚 you may want to check out if you’re interested in other areas of AI as well:
- How to get started with transformers and NLP
- How to get started with Graph ML
- How to get started with AI and ML in 3 months
Unfortunately, I made a mistake and didn’t write these blogs during the first 6 months when I was working on Neural Style Transfer (NST), DeepDream, and Generative Adversarial Networks — GANs.
Having said that, I did briefly describe that part of my journey in the “How to get started with transformers and NLP” blog, so do check it out if that’s something of interest to you!
If you need tips on how to learn more effectively and efficiently I recommend this one: “5 Tips to Boost Your Learning”.
GitHub projects 🤓
Also, I couldn’t be happier with the projects I open-sourced over the last 16 months. You may find them useful in your learning journey, they are super easy to get started with, just read through the setup section of the README:
- NST (Gatys et al.), NST-fast (Johnson et al.), NST for videos (naive)
- DeepDream (Mordvintsev et al.)
- GANs (original, cGAN, DCGAN)
- The original transformer (Vaswani et al.)
- Graph Attention Network (Veličković et al.)
- Deep Q-Network (Mnih et al.)
All of these were written in PyTorch. I also strongly recommend creating your own deep learning projects. You’ll learn a lot by doing — trust me.
YouTube videos 🔔
I also started my YouTube channel last year, The AI Epiphany 🔔, whose main goal over the last period was to share my story along the way, as I was learning myself. Going forward its main focus will be on the latest and greatest ML papers and beyond!
[New!] The monthly AI newsletter 📢 & a Discord community 👨👩👧👦
If you want to keep up with latest & greatest stuff happening in the AI world subscribe to this monthly AI newsletter and join the Discord community!
Aside from Medium, YouTube, and GitHub where I have a somewhat lower frequency of upload, I started sharing my daily AI updates on Twitter and LinkedIn — so if that’s something of interest to you check it out! ❤️
Before I did this ~1.5 year long deep learning exploration, my strongest background lied in computer vision, but after 16 months of strategically exploring other areas, honestly, I don’t identify myself as a “computer vision guy” anymore that’s for sure.
My goal was to build up knowledge breadth in AI (and depth as much as possible given the time I had, BFS basically 🤓) and I think I might have just done it. I decided not to pursue a PhD and to do it my way — and I’m happy with how things rolled out, although this path is definitely not for everybody.
Note: I haven’t been sharing everything I’ve been doing there was a lot of mathematics and classical ML involved as well. I found the book “Mathematics for ML” — Deisenroth et al. extremely valuable (I’ve read it twice). I started learning ML back in 2018 — so it’s not a 16-month journey in total obviously.
If you were following along, you knew that my next interest lied in RL, and so 2-3 months later here we are!
With that out of the way let’s start with the question “WHAT is RL?”.
✅ Intro
What is Reinforcement Learning? (RL 101)
Simply put, RL is a framework that gives our models (more commonly referred to as agents in RL) the ability to make “intelligent” decisions that help them achieve their goal which is approximately this one:
Maximize the expected amount of reward. (more on this later)
It’s super common to see a diagram like this one explaining, on a high level, what the framework is all about:
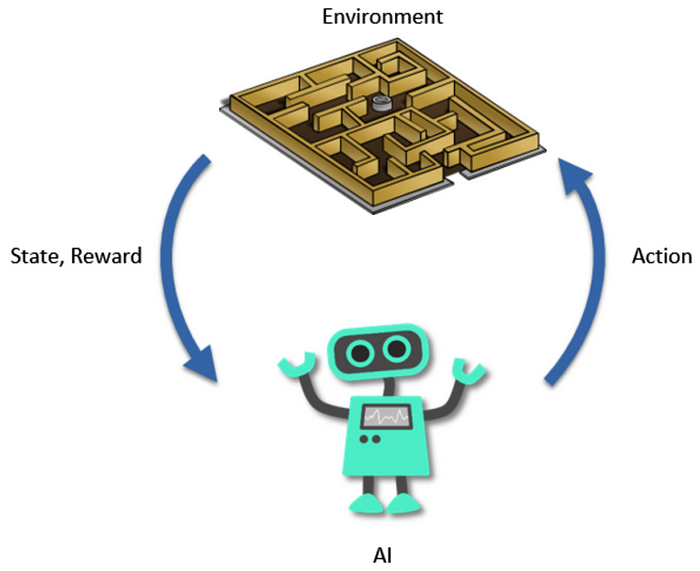
You have an agent interacting with the environment. It makes some actions and the environment sends back the reward for that particular action and also the next state of the environment.
Let me make it a bit less abstract! 😅 Abstraction is a great thing to have once you’re grounded in real examples otherwise it’s just poor pedagogy.
In the game of Pong (Atari), which I’ll be using as the running example:
- The state could be a couple of last frames (images of the screen)
- The agent could be a simple CNN (like the famous DQN agent)
- The actions could be: “move the pad up”, “move the pad down”, and “don’t move at all”.
- The rewards could be +1 if you win the game else -1.

And the goal of the Pong agent would be to learn how to maximize this scalar reward which hopefully correlates with our goals — and that is for it to become a great player at the game of Pong in this case.
You can immediately see some of the problems in RL (definitely not a comprehensive list, trust me on this one):
- The sparse rewards problem (+-1 only at the end of the episode)
- The credit assignment problem (which actions led to win/loss?)
- The problem of effectively communicating our goals to the agent
- The problem of exploration vs exploitation
Let me try to break these down for you. ❤️
Sparse reward
Unlike in supervised learning where the “reward” is dense i.e. for every single data point you have the correct solution (e.g. in image classification image-class tuples), here you don’t have a dataset that tells your agent where to move the pad in each state of the game.
For that matter, you don’t have the correct label (ground truth) in any of the states! You merely observe some rewards and you devise an algorithm that will map those rewards into some pseudo-labels.
Hence RL is considered a separate category of learning alongside supervised and unsupervised (there are also self-supervised and semi-supervised paradigms and there are overlaps between these, it’s not a clear cut).
The main criterion of this categorization is the following question: “Were the humans in the loop? Did somebody had to create the annotations/labels for the ML algorithm?”.
Credit assignment
Say your Pong agent accidentally won early in the training process, which of the moves it performed led to it winning the game?
The “move up” action 40 steps ago? The “don’t move at all” action 100 steps ago?
And that’s the credit assignment problem — figuring out a strategy to basically create good pseudo-labels for each data point you collect.
Effective communication with the RL agent
Choosing the right goal may seem trivial in the case of Pong, but let me prove you wrong. 😅 (don’t hate me for this I know everybody wants to be right!)
Here is a super famous example where we implicitly stated a goal by asking the agent to maximize its game score, with an actual intention/goal being that the agent learns how to become great at winning races, but it ended up just learning a pathological behavior:
It did accomplish the goal we gave it but that wasn’t the goal we meant.
Now imagine a system way more complex than a simple game. Also, imagine people’s lives being at risk and you’ll understand the weight of this problem.
You could choose to shape the reward in order to be more explicit in your communication but that won’t lead us anywhere over the long run, plus it’s hard and time-consuming. Take a look at this reward function (the goal was for a robot to learn to pick up stuff):
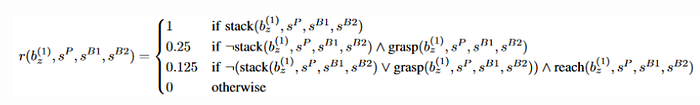
As you can imagine designing this reward was hard and it doesn’t generalize.
All this reward chit-chat leads us to the next important question.
Exploration vs exploitation
Once the agent finds high reward states should it continue to visit them (exploit) or should it allow for some exploration which may lead to a discovery of even higher-reward states?
That’s one of the main dilemmas in RL, and in humans for that matter!
Say you’ve been to 10/40 restaurants in your neighborhood and you’ve found 3 of those which you really enjoy. Will you continue visiting them from now on or will you give yourself a chance to find a better restaurant? Potentially risking eating much worse food on that exploratory journey but with a promise of something truly great (like Kentucky Fried Chicken 🐥).
One of the classical methods for balancing exploration with exploitation is epsilon-greedy. Basically with an epsilon probability you pick a random action otherwise you pick an action that promises the highest reward.
Finally, you may have asked yourself how does this maximization of a sum of scalar rewards (reward ∈ R) translate to a desired intelligent behavior?
Well, basically, RL relies on this hypothesis (aka the “reward hypothesis”):
That all of what we mean by goals and purposes can be well thought of as maximization of the expected value of the cumulative sum of a received scalar signal (reward). — Richard Sutton
All of the words in the above sentence are there with a purpose, loaded with meaning, like expected and cumulative, but the goal of this blog is for it to be a meta-learning resource so I obviously won’t get into the nitty-gritty details and maths of RL but merely point you in the right direction and hopefully give you some good tips along the way.
The way we capture these cumulative sums of scalar rewards is usually via the Q-function (action-value function) or via the V-function (value-function). Q tells us the amount of reward we can expect starting from a specific state and picking a specific action whereas V tells us the amount of reward we can expect in a state. RL agents which use these are called value-based agents.
There are also policy-based agents which instead of trying to estimate the value that certain state/action will bring just try to learn which action to pick.
And there are those that combine the 2 — actor-critic methods. We could also have a model of the world or not (model-based RL vs model-free RL). The model tells you the state-transition probabilities but you don’t need to worry about it for now.
With that, you’re “good enough” to go. Don’t worry if you didn’t grasp everything in the first pass, you’ll have plenty of time.
With the WHAT question out of the way, let me give you a reason WHY you should even bother learning about RL! ❤️
Note (on how you should (probably) read the following chapters): I’d recommend not digressing too much into the resources I linked during your first read, do check out the shorter videos though. After that, I’d recommend exploring all of the resources I’ve linked in the following 2 sections just to get you hyped and to get a feeling for what RL has accomplished as well as the problems it’s facing. After that start following the resources I linked, approximately in the order I’ve linked them.
✅ RL 101
The awesome world 🌍 of RL
RL is an exciting and interesting paradigm and the only one I know of that promises the creation of an AGI. For that matter, it’s the only one which at least dares to try.
An RL agent can readily use the latest and greatest advancements from the worlds of CV, NLP, and Graph ML.
Computer vision gives it the “eyes”, the ability to represent the visual parts of its environment and to abstract the visual concepts. The breakthrough that the DQN made happened thanks to the breakthroughs in the computer vision world (more on DQN later).
NLP gives it the power to construct good representations of language concepts. NLP (transformers, etc.) enabled AlphaStar (more on it later) to better “understand” the game of StarCraft II.
Graph ML, e.g., allows it to understand the interconnectedness of visual and language concepts which I’ve mentioned above. They can be modeled as nodes in a heterogeneous graph.
Over the past decade, we had amazing accomplishments, previously unimaginable, happening in precisely the field of RL. Let me tell you about a few of those!
Note: Deep RL = RL + deep neural networks
Deep RL — the early days 🌌⭐
It all started with Deep Q-Network back in 2013. Before it, RL was mostly using the tabular setting for the state space (the collection of all states in the environment), which couldn’t scale to applications we actually care about since you need a slot of memory for every state in your environment.
DQN created a “new” field that we call deep RL. Deep stems from the fact that these RL algorithms are using deep neural networks as function approximations. With DNNs we only need a finite amount of parameters to capture huge state spaces (they are parametric models).
DQN managed to play ~29 Atari games at a human or super-human level. And all that with the same architecture, the same minimal setup, and directly from the raw images — something completely unimaginable in the world of RL prior to that.
Basically, the agent only receives an input frame (image), the number of actions for a particular game (which defines the number of outputs of a CNN) and the rest (the learning) is done via game specific scalar rewards.
You throw this very same setup in any one of the Atari games and it learns to play them (most of them at least — some of them like Montezuma’s revenge were a tough challenge up until recently).

A similar trend in the initial deep RL era was also made in robotics showing that we can train robots end-to-end (e2e) to perform certain dexterous tasks, like screw a cap onto a bottle, placing a coat hanger on a rack, etc., using raw vision and robot’s state (robot’s joint angles, etc.) as an input!
CNNs were powering this breakthrough as well.

Next came the almighty AlphaGo. The first program that won against the best human player in the world, Lee Sedol, in the game of Go. It’s also the only algorithm that came even close to doing that back at the time.
AlphaGo lineage 🐒 -> 👶
It was a big deal. Most AI experts didn’t expect that to happen for at least 10 more years. It was considered the “holy grail” of AI, solving Go.
The huge search space of the game (~250¹⁵⁰) seemed unsolvable. Chess, the ex-drosophila of AI, is funny compared to it (35⁸⁰) and yet decades of research went into cracking chess.
Yet in 2016, AlphaGo, trained with a combination of supervised learning, RL (self-play) and Monte Carlo Search Tree (MCST) did it.
This feat was such a big deal that millions of people were following the event. DeepMind even made a movie on it. It’s got 24 million views at the time I’m writing this (and no it’s not even a Netflix series 😂). I strongly recommend it, it’s a great story even if you’re not into AI per se:
Training AlphaGo took a massive amount of compute, more than a month on 50 GPUs to train the DNNs and I’m not even counting in the hyperparam search that led to this final model!
After AlphaGo even better agents appeared, the so-called AlphaGo lineage of agents: AlphaGo Fan/Lee/Master (incremental improvements), AlphaGo Zero, AlphaZero and finally MuZero.
AlphaGo Zero ditched the supervised learning part that relied on human play datasets and managed to beat the previous best AlphaGo 100–0! Throughout its training it reinvented the collective knowledge which humans had to collect over the past 2000+ years. And all of that through self-play RL.
AlphaZero further generalized the AlphaGo Zero agent and learned to additionally play Chess and Shogi (the so-called “Japanese Chess”) with pretty much the same model.
Finally, MuZero appeared. It had to additionally learn the rules of the game (none were given to it!) and it additionally could play all of the Atari games (on top of Go, Chess and Shogi). A new step towards more general agents.
All is not rosy though — the BIG problem with all of these is the fact they have to be retrained from scratch for every new game they play! There is no generalization that happens across the games.
But I’ll leave the problems RL faces for the next section — once the board games became “too easy” the community turned their eyes onto tougher challenges, like multiplayer real-time strategy games such as Dota 2 and StarCraft II.
The story of OpenAI Five and AlphaStar 🎮
The really hard part about these games is that:
- They are partially observable compared to previous board games we looked at (e.g. the fog of war doesn’t allow you to see the parts where your opponent is building his/her infra unless you have your troops there)
- The action and observation spaces are huge! The breadth of the decision tree is somewhere around 8k-80k in Dota 2, contrast that with Go’s ~250 or Chess’s 37 legal moves on average! Funny, right?
- Also, the time horizon of the game is very long. Humans play these games in ~45-minute sessions which means a huge number of steps for an RL agent. E.g. the decision tree’s depth =~20k in Dota 2, contrast that with Go‘s 150 moves.
Again, experts thought we’ll need lots of time to solve these. Some were more optimistic after Go was taken down. But soon enough we had bots winning at professional eSports games!
OpenAI started working on their Dota 2 bot called OpenAI Five back in 2016. A couple of years later in 2019, they have beaten the best human teams in the game of Dota 2.
They imposed certain restrictions on the game — like the pool of heroes humans could pick from was smaller than normally, certain parts of the bot logic were scripted instead of learned, but all in all, given more compute none of these change the fact that bots are truly better than humans in these specific constrained domains we call e-games.
You could also see a clear curriculum — they first started beating humans in the 1 vs 1 setting and only later tackled the 5 vs 5 setup. Which is smart, if you can’t win in the 1 vs 1 setting why even bother with 5 vs 5.
If you’re interested you can watch the finals here (I personally skimmed through the interesting parts mostly on 2x playback speed):
The main RL algorithm behind this was PPO which was invented a couple of years before. So it wasn’t that much the algorithmic innovation that got us here but the sheer compute and engineering, RL at scale!
An interesting parameter they had was “team spirit”. It basically was annealed from 0 to 1 during the training and it controlled the agent’s selfishness (0 — maximally selfish, only my score matters, 1 — only the score of team matters even if I die).
Compared to AlphaGo lineage what I found interesting here is the generalization capability — the bots were able to play against humans (compete) as well as to play with humans (collaborate) in a mixed-team setup even though they’ve never seen that play-style during their long self-play careers.
In this LinkedIn post, I’ve linked additional cool resources if you want to learn more about OpenAI Five. Now onto AlphaStar!
A similar story happened with StarCraft II and DeepMind’s AlphaStar bot. They trained AlphaStar using various RL and game-theory techniques — bunch of compute and engineering later it was beating the best humans at StarCraft II.
Arguably AlphaStar team tried really hard to make the game absolutely fair. The APM (action-per-minute) of their bot, the way it could see the world (initially it could see the complete map but later it could only see parts of the map — same as humans), etc. all mimicked the way humans play the game.
Again, if you’re interested here is a cool demonstration of the finals against one of the best StarCraft II players in the world (I watched the whole thing some time back and enjoyed it):
The main idea of the AlphaStar paper is the concept of the league of players, because the pure self-play, that worked so well with Go, lead to a circular progress (read no progress) whereby new agents can easily be exploited by simpler agents.
The league consists of:
- Main agents — these are the ones we ultimately care about
- Main exploiters — their goal is to find the weaknesses of main agents
- League exploiters — their goal is to find systematic weaknesses
In the interplay of main agents with themselves (SP) with exploiters as well as with older agents (so as to minimize forgetting), in the so-called fictitious self-play (FSP) they grow very robust.
Check out this LinkedIn post for more details.
Personally, one thing that I find weird is that they haven’t tried to beat the best of the best player in the world — like in Go. I can only assume why that was, and I guess it has to do with resources — even DeepMind occasionally gets to taste the reality like we, mere mortals! 😅
Shifting the focus from games onto robotics here are some amazing things that happened in robotics — RL intersection!
Robots, robots, robots 🤖
Learning Dexterous In-Hand Manipulation by OpenAI (codenamed Dactyl): This is definitely one of the projects that sparked my love for RL!
The goal of the project was to orient a cube into a specified target orientation using a robotic hand (Shadow Dexterous Hand) + RL.
Now the cool thing about it is that the RL agent was trained purely in a simulation, it was deployed to a real-world and it actually worked!
Check out this short demonstration:
The main algorithmic idea behind it was to use heavy randomization during the simulation so that the real-world seems like yet another incarnation of a simulation (wait, is it not? laughs in Elon Musk).
In the follow-up work they managed to improve it so that it can solve the Rubik’s cube! One of my favorite papers ever, TBH. It was such a multi-faceted project — a combination of mechanical engineering, electronics, robotics, algorithms, computer vision, RL, you name it!
Now, be careful here, the feat is not solving the Rubik’s cube per see (they use an off-the-shelf solver for that), but dexterity/controlling the hand when you know on a high-level what your next steps are (e.g. rotate the upper face 90 degrees clockwise).
Check out this awesome short demonstration:
They improve upon Dactyl by introducing an automatic domain randomization algorithm that automatically changes the ranges of randomization params in the simulation — like gravity.
It starts being calibrated to Earth (~9.81 m/s²) and depending on how much the policy is struggling the range will, eventually, expand to say 4–12 m/s². Thus this provides the agent with an implicit curriculum learning as the envs become harder and harder.
The agent had 13 000 years of cumulative experience! (counting in all the compute needed for the hyperparam search, training, etc. and keeping in mind that 1 step of simulation corresponds to 80 ms).
The part that blew my mind about this paper was the emergent meta-learning behavior. The hand learned to encode the params of the environment it is in, directly into LSTM’s hidden state.
They tested this by deleting the state at one point of the execution and noticed how the hand takes longer to perform the next few steps and later catches up to its previous speed.
They also showed that they can infer env params (like the size of the cube, gravity, cube mass, etc.) through LSTM’s hidden space — again showing that the hand learns to encode the parameters of the env it is in!
Finally, check out this short blog on how RL was used at Google to reduce the power consumption by a massive amount (~40%). The paper never came out and I’m decently sure that they needed to add bunch of hacks to make it work — so it’s not just RL that made this happen, keep that in mind.
You may have noticed that most of these accomplishments happened in the domain of super constrained problems like constrained robotics and board/video games, and you may have asked yourself why is that?
Well, that nicely brings us to the next section.
✅ Cool RL stuff (the WHY)
RL is not only roses (RL ∉ {🌹, 🌸, 🌻})
There are still many problems that are making it hard for RL to be useful outside of very controlled and/or simulated environments.
For start, RL is sample inefficient, a fancy way to say that RL requires a LOT of data & compute for it to work. The original DQN agent required ~200M frames for every single Atari game!
Check out this blog by OpenAI to get a feeling for the compute needed for some of the agents I mentioned in the previous section:
Pretty much only big tech companies can afford this much compute.
RL sucks at generalization. E.g. even MuZero has to be retrained from scratch for every single game in order for it to work. The fact that a MuZero agent can play Breakout on a super-human level doesn’t help it to learn to play Pong — which is weird, from the human perspective at least.
Somewhat related is this quote:
Deep RL is popular because it’s the only area in ML where it’s socially acceptable to train on the test set. — Jacob Andreas
Made me laugh the first time I read it. 😂 But it tells a story. We’re testing our agents on the very same environments in which we’re training them. How can we expect generalization to emerge? The lack of generalization in somewhat baked-in into the current deep RL paradigm.
Also, as I mentioned reward function design is hard, agents can learn pathological behaviors that don’t match the goal we envisioned, and even when they have a reward function that matches our goal they’ll often get trapped in a poor local optima.
Other than that RL agents are not very robust to changes in hyperparams, i.e. they are utterly unstable and thus the papers are hard to reproduce. Even a random seed can make a difference between your agent working and not!
Sometimes, just changing the random seed can make a difference between the agent learning how to accomplish a goal and it failing miserably.
Rather than trying to list everything that could go wrong I strongly recommend this blog by Alex Irpan who works at Google Brain on the Robotics team, he’s done the work for me (thanks Alex!):
Read it carefully, and let it sink in.
All those problems make it hard to reproduce RL algorithms. The “But it works on my machine” force is especially strong in RL.
Lastly, here is a video by Joelle Pineau from FAIR/McGill additionally explaining some of the main problems that RL is facing:
I had a first-hand experience with RL being hard to reproduce— I’m still debugging my implementation of the DQN agent, I’ll update the blog as soon as I get it working!
Note: TBH I wasn’t invested in it 100% because of the lack of time. But it definitely is harder than your average DL project, that much I can claim.
Nice, you got the yin and yang perspective of RL!
Having hopefully answered the question WHY, let me give you the tips on HOW you can get started with RL.
✅ Problems with RL
Getting started with RL 🚦
By listing all the stuff in the previous sections you’ve already started getting familiar with RL. Here I’ll try to structure it in a way that’s more suitable for building up solid foundations — I’m going to give you a strategy that worked for me.
I’m a huge fan of the top-down approach. You should start with high-level resources such as high-level YT videos and blogs and slowly work your way all the way down to reading papers.
Related to that I think it’s super useful to get exposed to the terminology of the field early on, so that you can let it sink in. Many confusions happen just because we don’t know the actual language, the syntax.
Tips out of the way, let’s start!
Out of all the YT videos I’ve watched I’d start with these ones:
- Intro to Deep RL and Reinforcement Learning from MIT
They are very basic and nicely structured, next up I’d watch this one:
Nuts and Bolts of deep RL by John Schulman from OpenAI will tell you about the common problems and strategies you could use to debug your RL algorithms.
In this stage of your learning process don’t beat yourself down for not understanding everything. Feel free to stop the video, google some concept and get right back into it. You should use the benefits modern tools provide us with.
Never be passive while learning. Open up a OneNote (or whatever your favourite note app is) on the other screen and write down concepts you found important. I also found it useful to write down timestamps and make a comment, others and future me will be grateful.
Also if some parts of the video are already familiar, hit that playback speed button — I often watch content on 1.5-2x speed (especially if I’m already familiar with the topic).
The bottom line is — you shouldn’t be watching YouTube videos like you’re watching your favourite Netflix series. You’re trying to learn, remember?
Lastly, I found this short video by Pieter Abbeel interesting as it gave hints of what it takes to make RL actually work in the real world.
After the videos, go through some high-level blogs:
- Pong from Pixels — Karpathy, amazing as always. You’ll learn a lot from it.
- Spinning Up — getting started as an RL researcher, you’ll find some nice ideas in here as well!
- This (get exposed to terminology), this (survey of RL) and this (build a simple snake app, nice ablations) to get you started reading about RL.
Then go through some simple code. I strongly recommend that you get exposed to RL code early on in your learning process. Code can sometimes be the best explanation of the concept you’re trying to understand:
- Vanilla Policy Gradients gist by Karpathy, and a great accompanying video, also this blog as well as this one can further help you understand Karpathy’s Vanilla PG implementation.
- RL adventure and RL adventure 2 — I’ve consulted the code snippets in these repos after reading a paper whenever there was an implementation of that paper. The code is often times overly simplistic, there are some bugs, but it paints an overall picture!
Finally take 4–7 days to go through David Silver’s course:
After that you’ll have heard most of the fundamental RL algorithms, problems and terminology, and David is a great lecturer so I believe you’ll enjoy it.
A word of advice here, I’ve said 4–7 days since I don’t recommend you binge-watch all of these in a day or two (even though you could). You’ll simply forget everything, you have to let it sink in.
Same goes with anything, if you hit the gym and do 4 trainings in a day that won’t make you stronger that will probably get you injured. Doing 4 trainings over a week on the other hand can bring you some progress.
Finally you can watch this Deep RL lecture by John Schulman (again)!
Note: If you really know that RL is something you want to do for the years to come I’d strongly recommend the following. Instead of jumping into reading papers in the next section, I’d invest a month of my time and I’d go through the famous Sutton’s and Barto’s book with a very intensive pace. IMHO, that’s a much better strategy than reading it over a prolonged period of time.
Sutton is one of the most influential figures in RL (if not THE most). They focus on the tabular RL case and will teach you all the necessary mathematics and formalism you need in order to deeply understand RL (no pun intended).
As an accompanying resource this repo has solutions to all of the problems in the book. Do use it while reading the book — again it’s all about being active while learning if you want to be more productive.
Having said that, I personally haven’t read the book yet (I did go through all of the other resources I mention) and I didn’t notice any bigger problems reading through the papers in the next section. There were some papers which I had problems understanding but that’s normal!
✅ A high-mid level understanding of RL
Let’s go deeper — reading papers
Once you have the high-level overview of the field and the terminology in place it’s time to go deeper!

Paper collection strategy 🔍
I’ll tell you the approach I took researching RL!
I roughly found the biggest names in the field and I’ve collected their most cited papers. I then sorted them according to the time they were published. Finally, I roughly split those into 2 batches again according to the timestamp.
Some of the main names I used were:
- Volodymyr Mnih and David Silver from DeepMind
- John Schulman from OpenAI
- Sergey Levine and Pieter Abbeel (now at Covariant) from Berkley
Now this is far from perfect and if left like this it would bias me towards 2, 3 research groups (but frankly the power law is real). But, along the way as I was reading through the papers I organically found some other interesting resources and I’ve added them to my list. That was the strategy I was using.
Also, I was lucky enough to be in an email correspondence with Charles Blundell and Petar Veličković from DeepMind 🧠. Charles shook up the list I compiled with the above strategy and proposed some other good papers.
Finally, here is a glimpse of how one of my directories with papers looks like:
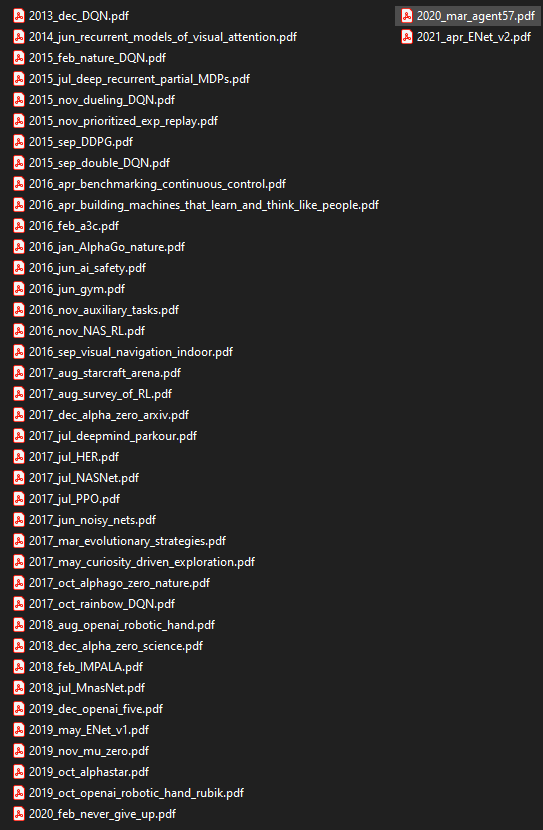
I split the papers I read into the following groups:
- The ones I still haven’t read (currently empty)
- The ones I’ve read and understood
- The ones I’ve read and had problems understanding
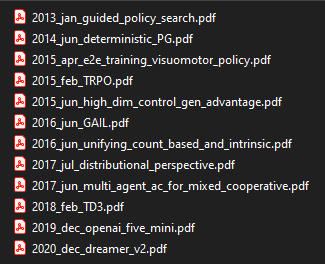
- The ones I’ve skimmed (only R2D2 paper)
- And finally the miscelaneous read — those are the papers I read along the way even though they are not necessarily related to RL. These either help me catch up on the prerequisite knowledge or they help me keep up my energy levels high! 🍎
Also as you can notice the first group contains papers like “Concrete Problems in AI Safety” or Evolutionary Strategies paper which arguably belong to this miscelaneous group but yeah it’s not a deal breaker.
You can also see that I’ve organized papers by the timestamp. I guess there are also platforms which could do all of this for me but this just does the job.
Note: don’t worry about the specific papers I’ve listed in there, in the next section I’ll list everything that you really need.
Hopefully this glimpse into my mind helps you a bit. And now!
RL papers list 📜📜📜
Let me try to introduce some structure into a pile of RL papers that’s out there.
Note: I’ll label the papers I had hard time reading with (#hard-read). This doesn’t necessarily mean it’s hard — it was so for me given the context I had at the time.
You should probably start by reading the DQN paper (Mnih et al.) which was a huge breakthrough at the time. I read both the arxiv (13') and Nature (15') versions, and I’ve covered DQN in this video:
Note: If you want to get a feeling for how RL is used in other subfields, like in CV, check out Recurrent Models of Visual Attention which has a nice example of how RL could be used in vision to emulate the way humans parse the visual space around them (multiple fixations interspersed by saccades and information integration throughout). It uses the simple REINFORCE (policy gradient) algo.
After the DQN was published it literally created an ImageNet-like moment for the RL world. A lot of research happened trying to improve upon DQN. Here are some of those papers:
- Deep Recurrent Q-Learning for Partially Observable MDPs — instead of stacking frames why not integrate the information over single frames using some sort of memory, LSTM in the case of this paper. They showed this is a viable alternative and that the model gains better robustness if the quality of observations (game frames) changes during the game.
The following papers led to the famous rainbow DQN paper:
- Dueling Network Architectures for Deep Reinforcement Learning — basic innovation lied in its dual-stream architecture, where one stream was estimating the value-function, the other one normalized advantage function and the fusion gave the action-value function.
- Prioritized Experience Replay — the main idea was to improve upon the uniform sampling of experience used in DQN’s replay buffer. Instead absolute TD-error was used as a proxy to choose pieces of experience which are the most valuable in the sense that they’ll accelerate learning.
- Deep Reinforcement Learning with Double Q-learning — deals with overestimation of Q-values by the regular DQN by separating the selection and evaluation stages of DQN (the idea was actually proposed in a tabular setting years before).
- Noisy Networks for Exploration — instead of using epsilon-greedy like the original DQN they baked the exploration noise directly into DNN layers.
- A Distributional Perspective on Reinforcement Learning — instead of finding the expectation of the reward (point estimate) this paper proposes to keep the whole value distribution during the training. (#hard-read)
And finally the rainbow DQN, “Rainbow: Combining Improvements in Deep Reinforcement Learning”, which combined the above research in order to engineer the best-performing DQN-like model back in 2017.
Learning tip: some of these papers use hardcore math and you may lack the intuition and fail to understand the mathematical formalism. Try and grasp the main idea, the semantics behind the paper if you’re having problems with the formalism. Watching YouTube videos before you start reading a paper is a strategy I sometimes find useful — although for most of these, unfortunately, it’s hard to find a (good) video.
Also if you feel you’re getting tired of the theory presented in a super formal way you need to find a way to bring your mental energy up! 🍎
Try reading up some interesting paper out of chronological order or watch an interesting video. I’d suggest you read this paper by Joshua Tennenbaum:
If you’re passionate about the whole AGI endeavor it’ll provide you with some refreshment! Or go ahead and read something lightweight so that you think you’re smart (😂) like the OpenAI gym paper. Power naps also help.
After that I’d recommend you read these papers from 2016:
- Asynchronous Methods for Deep Reinforcement Learning (A3C) — seminal paper, introduced the multi-threaded advantage actor-critic setup. The parallel actors stabilize the training without any use of replay buffer. In RL scale plays an important role and so detaching from the single-threaded setup of DQN was very important.
- Continuous Control with Deep RL (DDPG) — they generalize the success of DQN to the continuous domain such as robotics tasks using deterministic policy gradient + DNNs stabilized via similar ideas like DQN. It’s an actor-critic algorithm as well.
- Benchmarking Deep RL for Continuous Control — (introduces RLLib and gives a nice overview of the common tasks and overview and comparison of RL agents like TRPO, DDPG).
I’d wrap up this part with “RL with Unsupervised Auxiliary Tasks” (UNREAL agent) paper. The main idea is to cope with the sparse reward problem that RL agents are facing. So aside from maximizing the cumulative reward (extrinsic) they introduce pseudo-rewards (intrinsic) given by unsupervised auxiliary tasks like learning to maximize the pixel intensity over the input image (as a proxy to an important event in the env). It drastically improved the sample efficiency of A3C agent (~10x less data).
Now, If you’re like me one of the papers you were excited to understand is AlphaGo:
It is one of those projects which couldn’t have been accomplished using any other method, where RL really shined to its fullest!
I’ve covered it in this video as well:
Yes, I love this picture with those glorious mustaches. Now let’s continue.
One of the main components of AlphaGo is Monte Carlo Tree Search or MCTS for short. If you’re not familiar with it I found this video was great at explaining it.
While the AlphaGo knowledge is still fresh in your mind you can go ahead and read the whole saga (for my CS nerds: before any context switching occurs!):
- Mastering the Game of Go without Human Knowledge (AlphaGo Zero )— a step towards more general RL agents, it ditched the SL part of training that relied on human play datasets and focused purely on the self-play.
- Mastering Chess and Shogi by Self-Play with a General RL Algorithm (AlphaZero )— further generalized the algorithm to play Chess and Shogi.
Here is a video covering both papers (since they’re very similar):
And finally, MuZero which additionally learned to play the Atari games as well as the rules of the game!
The part with how the hell can it learn the rules of the game used to bug me, I’ve explained the paper as well as that specific part in this video:
There are many additional cool resources out there on AlphaGo lineage of agents. I’d recommend reading all of DeepMind’s blogs you can find like the one on MuZero and this one on AlphaGo Zero.
After getting back from this tour of the AlphaGo world you can now return back to reality and start reading RL papers for mere mortals. Here are some additional papers you should read:
- “Target-driven Visual Navigation in Indoor Scenes using Deep RL” — the cool thing about this paper is that they try to tackle the generalization problems present in RL. Instead of baking the goal directly into DNN’s parameters they can flexible change the goal — the target location where they want the robot to go. They test the agent in progressively harder generalization tasks. Kudos.
- “Emergence of Locomotion Behaviours in Rich Environments” (aka DeepMind parkour paper) —instead of reward shaping they show that the agents can learn interesting behavior on their own when given progressively harder environments (implicit curriculum learning). Definitely check out this paper and the video below:
- Hindsight Experience Replay (HER) — similarly to UNREAL they tackled the sparse reward problem. The main idea is the following, say you want your robot to move to a position (x1, y1) but it instead moved to (x2, y2). Instead of dropping this trajectory you can do the following, imagine your goal was precisely (x2, y2) that means that whatever robot did was correct we just need to change the goal post hoc! Hence the “hindsight” part.
- Curiosity-driven Exploration by Self-supervised Prediction — proposes the Intrinsic Curiosity Module which acts as a source of intrinsic reward (extrinsic reward comes from the environment like in Atari the score you get after every move, intrinsic comes from well, within). Check out this post for more details.
- Survey of RL — you should occasionally read these to get the breadth and organic growth of your paper list as you’re learning. Just be careful not to inflate your list just for the sake of it. (Charles recommended this one)
Finally before you get to the arguably most popular and interesting RL projects (aside from AlphaGo) you’ll need to read 3 more papers:
- Proximal Policy Optimization (PPO, OpenAI) — very impactful paper used in many RL papers. Even DeepMind parkour paper used it. OpenAI used it for OpenAI Five bot and robotic hand project.
- Domain randomization paper from OpenAI — showed how smart randomization in a simulation can help models generalize fairly well to the real-world.
- IMPALA (DeepMind) — used in e.g. AlphaStar. Allows for amazing scalability, more compute = more results, remember? 😅
Skill unlocked. Given infinite compute you could now solve anything in this world! That’s just an implementation detail, it shouldn’t be a deal-breaker…
Right?
Now, you could first research the AlphaStar saga by reading these 2 papers:
- StarCraft II: A New Challenge for RL — describes the API and some details you’ll find useful reading the AlphaStar paper I suggest you at least skim it.
- Grandmaster level in StarCraft II using multi-agent RL (AlphaStar)
After you’ve read through the AlphaGo and AlphaStar papers I’d also recommend this video by David Silver.
Next up you could investigate OpenAI’s robotic hand saga, start with the official blogs Dactyl and Rubik. I also covered both of these in this video:
as well as this one by Marcin Andrychowicz, one of the co-authors from OpenAI.
and only then head over and read the actual papers (remember? top-down):
Last but not least OpenAI Five!
I wrapped up my RL exploration with Agent 57 lineage. The first RL agent to crack (go above the human baseline) all of the 57 Atari games, including Pitfall, Solaris, Skiing and Montezuma’s revenge:
Search for the blogs and read these papers (Agent 57 builds right on top of R2D2 and NGU so make sure to check those out):
- Recurrent Experience Replay in Distributed RL (R2D2)
- Never Give Up: Learning Directed Exploration Strategies (NGU)
- Agent57: Outperforming the Atari Human Benchmark
Charles Blundell, the co-author, covered these beautifully in this video:
Also, something from 2021, the recently published Dreamer v2 is the first single-threaded, model-based agent that outperformed the Rainbow DQN that took years of incremental research to craft:
Check out the paper here:
- Mastering Atari with Discrete World Models (Dreamer v2)
Yannic Kilcher also made a nice video on it.
Wrapping up, I’ve skipped some papers which are more theoretical, harder to read, and not necessarily needed in order to understand the resources I’ve linked above, but are still a good read!
- Addressing Function Approximation Error in Actor-Critic Methods (TD3) tackled the overestimation bias in TD methods that was present in the continuous action spaces with actor-critics (similar to what double DQN paper did for the discrete action spaces).
- Unifying Count-Based Exploration and Intrinsic Motivation — another intrinsic motivation method, achieved great results with Montezuma’s Revenge at the time.
- High-Dimensional Continuous Control Using Generalized Advantage Estimation — introduces GAE a novel RL method that pulled ideas from TD(lambda) and TRPO to cope with data efficiency and stability.
- Trust Region Policy Optimization (TRPO)— PPO simplified it and since then I haven’t seen TRPO mentioned a lot (I may be wrong!). This blog by OpenAI helped me better understand it.
- End-to-End Training of Deep Visuomotor Policies and Guided Policy Search — lots of robotics/control theory inside that’s what makes it a harder read I have little experience with those subfields.
- Deterministic PG — devised a method that outperforms its stochastic counterparts in high-dimensional, continuous action spaces. And it’s much more efficient as well.
✅ RL papers!
And now, as always, I’m a big fan of actually coding something up and not just focusing on the theory and papers. The devil is in the details as they say!
Here are some learnings from the DQN project I did!
Deep Q-Network project from scratch
I didn’t have that much time lately to focus on the project but nonetheless, I can say that debugging and creating RL projects is harder than your average ML project — for the same reasons mentioned in the “RL is not only roses” section.
Nonetheless I learned a lot! And I’ll keep doing so until the project is done! ❤️
You can check out the project here:
Here are some of the problems off the top of my head which I’ve encountered with OpenAI’s gym library:
- Had to downgrade to 0.17.3 because Monitor had a video recording bug
- Installing atari on Windows is not smooth but there is a simple workaround.
- You sometimes need to dig into issues and source code, e.g. to figure out those cryptic env naming conventions like “PongNoFrameskip-v4”.
- Gym random seeds do not work as expected.
- Gym’s atari preprocessing has no frame-stacking, it’s simply a max-pooling over the last 2 observations.
And there are some problems with all of the DQN implementations that I’ve looked at in general:
- Toy replay buffer — saving (1M, 4, 84, 84) bytes instead of (1M, 1, 84, 84 (even stable baselines 3 is having problems with replay buffer! — my issue)
- Most of the repos don’t have a readme stating the achieved results. Have they managed to get results comparable to the published results?
Debugging this thing is hard and slow. It takes me ~5 days to train the DQN on my machine (although I may have a bug) and so I understand why regular people haven’t been posting their results — they probably haven’t achieved the published results in the first place.
Check out this LinkedIn post for more rant! ❤️
Another great blog with which I can now completely relate to is this one by Amid Fish on reproducing deep RL projects.
Note: If you want to understand Atari preprocessing a bit better check out this blog.
I’ll update this section of the blog as soon as I get it working.
✅ DQN project
My next steps
If you stuck with me until here, congrats! ❤️
Hopefully this blog will inspire you to take your first step into the world of reinforcement learning! Or in general, I hope it’ll motivate you to keep self improving and learning every single day!
One thing you’ll notice after studying RL for a while is how many related subfields there are like (similarly to Graph ML):
- AI safety — imagine this example: A robot knocks over a vase because it learned that it can move a box faster to another location by doing that. Can we achieve the goal without specifying EVERYTHING that the robot SHOULDN’T do? Those are the types of problems we have to think about. You could start exploring this field by reading the Concrete Problems in AI Safety paper from OpenAI. Check out my summary.
- Robotics and control theory in particular
- Inverse RL and Imitation Learning
- NAS (neural architecture search) — the original NAS paper used RL. Since then other more compute-efficient methods have been advised but RL still has its place in the NAS subfield. I did a “detour” into the NAS field and I enjoyed it, here are some seminal papers you should read: NASNet, MnasNet, Efficient Net v1 and v2 (just recently published!), NAS survey paper, MIT OFA, Mnet v1, v2, v3, DARTS and this video and this high-level overview. Also, I’ve recently covered Efficient v2 in this video:
- Evolutionary algorithms —An alternative to RL, a type of black-box optimization method, i.e. you don’t need to know the exact structure of your loss function (like you need to when you do backprop). Perturbing the weights, evaluating them in the environment and forming a weighted average using those weights and rewards leads to better agents. Evolution strategies paper is a good starting point and my summary. This blog as well+ code snippets should be enough to get you started.
Also if you’re super curious and you want to understand more about this great moment from the game history skim the DeepBlue paper. I’ve made a summary in this LinkedIn post as well.
And as I said in my previous blog, I’ll tell you that exploring can feel overwhelming at times. You think you’re starting to grasp everything and all of a sudden a whole new subfield emerges. And I’ve been doing this for a while after I’ve finished my EE studies. So take your time and try to enjoy the process!
As for my next steps, I now feel I’m ready to start keeping up with SOTA across different AI subfields. That means that I’ll completely focus on building the AI community of people passionate about AI and tech in general.
I’ll:
- Start keeping up with the newest stuff in AI on a daily basis. My plan is to invest 3x15 mins daily to skim Twitter, LinkedIn and Facebook groups for AI news, which I almost never have the time to do. Consequently I’ll read the SOTA papers as they come out and I’ll cover them more regularly on my YT channel.
- Make regular (hopefully daily) paper/AI news overviews on Twitter and LinkedIn so if that’s something of interest to you feel free to follow me/connect with me there!
- Periodically (every 2–3 months) develop my own interesting and creative AI projects instead of implementing other people’s work.
- Occasionally write on Medium, especially when I have something super interesting to tell you or something long-form.
There is one more thing that I’m currently working on, which I can’t yet share, but I’m super, super excited about it. Hopefully, I’ll soon be able to share it! If that happens I can only tell you it’ll be a dream come true for me pretty much.
Hopefully, this inspires you to start creating your own plans and to keep on (deep) learning!
If there is something you would like me to write about — write it down in the comment section or send me a DM, I’d be glad to write more about maths, statistics, ML & deep learning, computer science, how to land a job at a big tech company, how to prepare for an ML summer camp, anything that could help you.
Also feel free to drop me a message or:
- Connect and reach me on 💡 LinkedIn and Twitter
- Subscribe to my 🔔 YouTube channel for AI-related content️
- Follow me on 📚 Medium and 💻GitHub
- Subscribe to my 📢 monthly AI newsletter and join the 👨👩👧👦 Discord community!
And if you find the content I create useful consider becoming a Patreon!
Much love ❤️
