Get Started with AI and Machine Learning in 3 Months

Machine learning and AI hype are here, it’s real, everybody is talking about AI and yet only a few understand what is actually happening, what is true, and what is media hype. We live in a time of media manipulations, where if you are not educated in different fields, and you lack critical thinking ability, you can easily get manipulated (without even knowing it).
The AI hype is often, let me debunk it, misleading as we are not yet near the AGI (Artificial General Intelligence) aka the singularity, even though many are trying to convince you otherwise.
Deep learning is really good at pattern recognition and perception but not at all at cognition. Nonetheless, AI is here and it is bringing a huge value to society already.
I am writing this blog post because a lot of people asked me how to get started with AI & ML and make that first step into the field.
I will give you a 3-month program, a blueprint, which you can follow even if you are working full-time (as I have been working for Microsoft at Microsoft Development Center Serbia, as a software engineer). I’ll also give you some advice on where to head next!
But first, let me tell you a bit about why you should (probably) listen to me.
A personal update, September 4th, 2021: well a couple of years after I originally wrote this blog I landed a job at DeepMind as a Research Engineer!!! ❤️ I guess the techniques I presented in this blog were a good strategy after all. 😅
Who am I? 👋
Even though I actually did a bachelor's in electronics, during my studies I was always inclining towards software engineering — taking courses from the CS department, working on small projects out of fun, curiosity, and also ambition.
The real change for me started when I went to Germany, Freiburg in the summer of 2017, to work there for 3 months as an Android dev. A couple of months earlier I got this internship and I decided to start improving my developer skills in Android programming. I created a couple of cool and simple Android apps and even published one on Google Play Store.
(As long as I’ve known myself I was always into self-education. I am also a big fan of 3 months intervals, I think that’s a perfect time unit for gaining a solid foundation in an arbitrary topic, be it software/ML, sports, languages — you name it.)
During my Germany period, I got interested in algorithms and I wanted to land a job in some of the big tech companies like Microsoft, Google, Facebook, Dropbox, Palantir, etc. So I started learning algorithms and data structures. I used the 3-month scheme and eventually landed a job at Microsoft (it was a struggle!), where I recently started working full-time, as a software engineer.
It’s an understatement to say I love it! I got a job in a team called Microsoft Cognition and it’s all about computer vision, machine learning, digital image processing, and holograms. Sadly, I am not allowed to talk about all the super-cool projects we do there, but you got to take my word on it.
During that period while I was trying to land a job at big tech companies (and had a parallel effort of going to hackathons, datathons, and meetups) I applied for this machine learning summer camp organized by Microsoft people from Belgrade, Serbia and I passed the qualification round!
Back at the time, I didn’t really appreciate how good the summer camp actually is and how only 25 out of ~300 people pass the qualification rounds and get a chance to work with some of the smartest people in the world. Lecturers from DeepMind and Microsoft Research to name a few.
That was my first experience with ML (summer of 2018). I already had a decent background in digital image processing and some basic knowledge of computer vision which helped me bridge the gap between pure SE and ML.
Aside from that, I’ve been to Brazil in the summer of 2018 (right after the ML summer camp) where I did an “internship” (it was more of a life experience than a tech internship), and shortly after my arrival to Brazil I got a job offer from Microsoft that I mentioned, and so I returned back to Serbia. 😂
Since then I’ve been studying machine learning and here I will try to give you my best advice on how to gain a solid background in a 3 month period.
(In the meantime, I became a part of the organization of the very ML summer camp I visited last summer and also a part of the organization of Microsoft’s internal ML course, where I recently had the honor to assist a workshop that was held by one of my colleagues, Nikola Milosavljević, who received his Ph.D. from Stanford!)
A short note before you start — I am still not an expert at Deep Learning. I have only started reading research papers and implementing my own projects. In this article, I am going to write about everything that I found helpful when I started.
Enough about me, there’s a lot of work to do, let’s get started!
Update, April 2020: A lot has happened since I last wrote this blog. It’s been a hell of a learning journey! I’ll probably either write a second part or update this one. In the meantime, I started my YouTube channel on AI (mostly focusing on computer vision — for now) so make sure to check it out:
Update, August 2021: A lot more has happened in the meantime! Like I’ve quit Microsoft, but here is something you may care about: I created a 📢 monthly AI newsletter and a 👨👩👧👦 Discord community! Subscribe/join those to keep in touch with the latest & greatest AI news!
Machine learning guide through the galaxy 🚀🌌
What background do I need, before I start?
- Basic linear algebra (nothing fancy, matrix multiplication basically)
- A bit of calculus (don’t panic! Chain-rule will cut it)
- Basic programming skills (Some experience, preferably in Python)
What if I don’t have this skill?
Linear algebra. You really, believe me, won’t need anything fancy from linear algebra to start. If you really feel though that you need some recap of the linear algebra I would recommend going through:
- 3Blue1Brown’s YouTube playlist (amazing channel in general!)
- Linear algebra course on MIT by Professor Gilbert Strang (I just skimmed some lectures myself, there may be better/newer resources out there)
Don’t get intimidated! You will mostly need to know what a vector is, what a matrix is, and what is matrix multiplication, simple stuff. For start.
If you want to follow along with my 3-month plan, honestly feel free to ignore the MIT course (it’s time-consuming), at least for now, because linear algebra is definitely a good toolkit to have especially if you want to become an ML researcher one day!
Calculus. The only thing you actually need to know is the chain rule and the concept of a derivative. Get an intuition for what it is!
Again going through this should suffice:
- The essence of calculus (3Blue1Brown).
Python. As far as Python goes, if you have any previous background in programming, where you developed the correct programming/algorithmic mindset and you understood the basic paradigms of programming (procedural/imperative, OOP, and functional) you won’t need any ramp-up.
Just use the good ol’ Stack Overflow on the fly.
Additionally, other knowledge that may come in handy (definitely not a prerequisite though) are algorithms & data structures, and some basics of probability theory.
I will assume that you satisfy all of the above, so you are ready to go!
I will split the program into 2 logical units:
- The core unit — that will give you some solid ML foundations.
- The extras unit — that will give you some context on what is happening in the world of AI and put you on the right track so that you can keep improving your ML knowledge.
The core unit
The core effort will be around Coursera courses. I assume you already heard about this really great learning platform, if not, well you have now!
Update, October 6th 2021: this blog still contains very relevant information and a good strategy to get started with ML!
I’ll just add that aside from Coursera the fast.ai’s course “Practical Deep Learning for Coders” may be an excellent alternative! Make sure to check out this LinkedIn post to understand what track to take! I still recommend you read the rest of the blog as the same principles will apply no matter which track you pick. ❤️
Course #1 — Machine Learning (estimated time: 1 month)
What is it about?
If you don’t already have a broad overview of what ML is about, and I assume you don’t as you are reading this blog post, start with this ML course on Coursera, offered in collaboration with one of the best universities in the world— Stanford — and lectured by one of the godfathers of AI — Andrew Ng:
The course lasts 11 weeks, but I did it in less than a month doing many things aside from it, so I labeled it with an estimated time of 1 month.
Note: If you want to get a LinkedIn certificate you will have to pay 79$ for this course (this may change so double check). Or you can also apply for financial aid if you can’t afford it. Though every resource is also available without paying for the course, so you are good to go.
What will you learn?
You will get a really solid overview of what is out there in the world of ML.
It starts by covering the very basics like what is ML and how it relates to AI and deep learning.
(Note: for now don’t worry if all these words mean nothing to you)
You’ll learn the basics of ML & linear algebra: what is gradient descent, what is a loss function, what is the difference between classification (output you are trying to predict is a discrete variable, is this a cat or a dog?) and a regression (output is a continuous variable, e.g. predict the price of a house), etc.
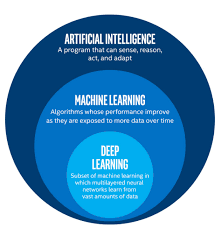
The course will also cover neural networks (deep learning), explaining concepts such as the forward and backpropagation algorithms — which are the core components for training neural networks (that’s how NNs learn).
It’ll explain the main problems that can occur during an arbitrary ML model training, like underfitting and overfitting (whether you’re dealing with neural networks or with more “classical” methods such as the SVM — you’ll have to deal with these!).
For example, in the image below, the model is trying to learn a discriminative curve in a 2D space where the goal is to separate green crosses (class 1) from the red circles (class 2). What is the optimal curve here ask yourself?
Well, you don’t want the rightmost scenario as there are some unseen examples (that you may care about in the future) that will fall on the wrong side of the curve. It’s fitting the data “too well” i.e. it’s overfitting.
And you also don’t want the leftmost scenario because it obviously doesn’t understand the data distribution. So the middle one is a sweet spot!

The course will also cover the main learning paradigms such as supervised (you have the labels) and unsupervised (no labels provided by humans) learning, and a slew of different ML algorithms like:
- k-means clustering — e.g. cluster news articles depending on the topic into science articles, sports articles, etc.
- PCA — project your data into a lower dimension space (2D or 3D), while minimizing the loss of information, in order to visualize your data.
- SVM (support vector machine) — a classification model.
- Linear regression — the image above is an example of linear regression even though the curves are not exactly lines (don’t ask me why! 😂).
- Stochastic Gradient Descent — a variation of the gradient descent algorithm that is used in practice.
But, theory without any practice is a bad teaching methodology so in this course you will also do some cool proof-of-concept projects!
Both supervised learning projects:
- Apply a linear and logistic regression to a toy labeled dataset in order to predict some value of interest (like house prices).
- Create a simple hand-written digit recognizer (dataset: MNIST ).
- Create a spam classifier — that’s what your fav email client (like Gmail) is doing in the background (dataset: Spam Assassin Public Corpus).
As well as some unsupervised learning projects:
- Perform an image compression and visualize the dataset using PCA (dataset: labeled faces in the wild).
- Perform an image compression using k-means clustering.
- Create vanilla recommender systems (think Facebook’s news feed, etc.).
After you finish this course you’ll have a rough picture of what is out there in the world of machine learning. Now, it’s time to start filling in the gaps!
Course #2 — Deep learning specialization (estimated time: 2 months)
What is it about?
This course will get you deep into deep learning — a special subset of ML techniques that leverage (usually) neural networks with multiple layers (hence the word deep). Deep learning is already bringing a huge value to society (especially the supervised learning paradigm)!
Be it YouTube’s or Facebook’s recommender systems, Facebook’s face-tagging features, Tesla’s and Waymo’s self-driving cars, speech recognition systems you name it. They all use deep learning, often “end-to-end” deep learning approaches but the “hand-engineering” approach still has its place.
Note — If you want to get a LinkedIn certificate you will have to pay 49$/month for this course, you can also apply for financial aid if you cannot afford it. Though every resource is also available without paying for the course.
What will you learn?
This course actually consists of 5 sub-courses, let me tell you what you will learn in each one of them:
- Neural networks and Deep Learning
You will get some hands-on experience with Python and NumPy (Python’s fundamental package for scientific computing). It’s a great tool for data pre-processing, manipulating matrices, and many many other things.
You will create a simple image classification model, using a logistic regression method, which will help you classify images into ‘cat’ or ‘non-cat’ (super useful with all those cats on the internetz of modern society! xD).
You will implement your first deep neural net from scratch and get an understanding of how things work “under the hood”. You will see how this model drastically improves the accuracy on the cat classification task.
Word of advice: Spend some time understanding the back-propagation algorithm for batch gradient descent. Dedicate 1 whole day only for this, and try deriving the equations of a simple neural network with 1 hidden layer. Use paper and pen. Make sure to derive equations:
- That are in a vectorized form.
- That hold true for the whole dataset and not only for a single example.
Believe me, it will be worth it once you understand it. Backprop is used everywhere, and the sooner you understand it — the easier your life will be.
Hyped already!? ❤️ With NNs in your toolkit the world is yours.
2. Improving Deep Neural Networks: Hyperparameter tuning, Regularization, and Optimization
This one is a mouthful. You will learn how to initialize your neural net’s weights, how to use L2-regularization as well as the dropout technique to avoid overfitting on the train/dev datasets.
You will learn about different optimization algorithms. You will basically build gradient descent on steroids, algorithms such as RMSProp, gradient descent with momentum, and one of the most powerful optimizers— Adam.
You will also learn how to split your dataset into mini-batches and use gradient descent on those mini-batches which will speed up the learning!
At the end of the course, you will learn a bit about TensorFlow, Google’s powerful deep learning framework, which you’ll use to create a simple vanilla neural network model to solve the signs dataset classification problem:

Basically, the net will be able to recognize various signs. Giving computers the ability to see, isn’t that awesome?
Quick note: the course focuses on Tensorflow and Keras as those were the most popular frameworks back when the course was created. In the meanwhile PyTorch became another great option! Check out my YouTube video for a comparison between these 2 frameworks.
3. Structuring Machine Learning Projects
Now that you know how to build, optimize and regularize your NNs it’s time to learn some ML system design.
The course gives you some best practices such as:
- Make the components in your pipeline as independent (orthogonal) as possible (meaning you can tweak only one of the components and not worry whether it’ll change the behavior of other components, this is a good practice for software engineering in general and not just ML).
- Always have a single number that tells you how good your model is.
- How to split your dataset into train/validation and test sets. Good splitting is very important if you wish to know how well your model will perform once in production.
- Carrying out an error analysis is important. By looking at the examples on which your model performs poorly you can improve it!
Also, you’ll learn about transfer learning, a really powerful idea that lets you take a pretrained network (that maybe took 100 GPUs to train in a Google data center!), and use it to crack your own problem. You’ll only need to fine-tune it on your (usually significantly smaller) target dataset and problem solved!
Basically, this subcourse gives you some engineering best practices which are really important once you actually start developing your own models.
Next up!
4. Convolutional Neural Networks
Pretty much the go-to approach for solving anything computer vision related!
CNNs made a quantum leap in the world of computer vision back in 2012 — a so-called AlexNet CNN left all of the other algorithms in dust, winning the ImageNet competition that year.
(ImageNet challenge was about classifying an image into 1 out of 1000 given classes — that used to be a very tricky problem for computers!)
You will learn how to implement CNNs starting with pure NumPy and later also by using advanced deep learning libraries such as TensorFlow and Keras.
You will implement some state-of-the-art (SOTA) architectures such as ResNet and you’ll learn about various other architectures such as AlexNet, InceptionNet, etc.
For me learning about neural style transfer (NST) was particularly interesting, as I love art. Here is an example I created:

But you’ll also find out about face recognition, real-time object detection (YOLO is a popular model), and other really cool CV applications!
Update, April 2020: I created a neural style transfer playlist on my YouTube channel feel free to check it out if you want to learn more about how NST works!
5. Sequence Models
This family of models is really great for solving NLP (natural language processing) problems!
You’ll be implementing unidirectional RNNs (recurrent neural nets) directly in NumPy that’ll help demystify the model. You’ll also learn about more advanced RNNs like GRUs (gated recurrent units) and LSTMs (long short-term memory).
Again theory without any practice is suboptimal, so you’ll be building a character-level model which will help you invent new dinosaur names, or write Shakespeare-like sentences! And you’ll also generate your own jazz melodies by modeling the underlying patterns of a given dataset.
And you’ll hear about many other cool NLP applications such as machine translation (translating between human languages) and my personal favorite trigger word detection (think “Hello Google” or “Hey Alexa”).
I really like the concept of machine translation encoder-decoder models. These models basically encode a sentence into a single vector (of which you can think of as a thought) and then they decode that abstract “thought vector”, using a decoder, into a target language!
Update October 2020: in the meanwhile, I’ve built a machine translation system from scratch! Using a model called transformer (you’ll be hearing a lot about them). Check out the code on my GitHub if you’re curious (470+ ⭐s and counting!).
Also, for quite some time already I was thinking about implementing some keyword spotter/detection model which I could use to turn my room lights on and off, as I am sometimes lazy! 😅
At the end of this “core effort” section I have one more piece of advice:
Go through the courses in sequential order!
You will thank me later.
Even though they say you can start with any course, you’re actually gradually building up the necessary knowledge going from course 1. through 5.
And that’s it! After you finish both of these courses you’ll be on your way to landing your dream ML job (or starting your own company/whatever you want to accomplish)! The final ingredient is the next section.
The extras unit
In this section, I will give you some of the other great resources I’ve been using during my 3-month long, Coursera-based curriculum.
The Artificial Intelligence podcast by Lex Fridman
Best AI minds in the world in one place — a podcast hosted by a great guy and deep learning researcher at MIT — Lex Fridman. This one will help you get a solid grasp of where we currently are with AI and where we are heading to!
Update, October 2021: Lex Fridman became very popular since I first wrote this blog back in 2019. His podcast used to be focused solely on AI people, whereas nowadays he brings in people with various backgrounds. I recommend you start with the oldest videos in this playlist and work your way up.
My top 3 videos, AI-focused, are:
- Building machines that see, learn and think like people — Josh Tenenbaum
- OpenAI Meta-Learning and Self-Play — Ilya Sutskever
- Statistical learning — Vladimir Vapnik
Aside from AI, there are talks on robotics, software, universe, consciousness, and so on. From this group my top 3 videos are (at the time I’m writing this):
- Computational Universe — Stephen Wolfram
- Boston Dynamics — Marc Raibert
- Stack Overflow and Coding Horror — Jeff Atwood
The AI people on Twitter
I would also strongly suggest you follow some of the best AI people from the industry/research on Twitter! You may be initially surprised with this advice if your main association with Twitter was Donald Trump. 😅
It turns out Twitter is a hub when it comes to AI-related topics. Pretty much all of the best AI researchers and engineers are actively posting on Twitter on various AI-related topics.
This is probably the number #1 way to stay up to date with the field! Aside from reading research papers. (update: and following my YouTube channel! ❤️)
Now, curating the people you follow is tough and takes time. Your network should grow organically.
But for the initial bootstrap, you can check out the people I follow.
Also, to get you started here are some “AI influencers”:
Yann LeCun (Turing award winner — “AI Godfather”), Geoffrey Hinton (another “AI Godfather”, not so active on Twitter), Jürgen Schmidhuber (a guy who should have been a Turing award winner 😅), Andrew Ng (Coursera founder), Andrej Karpathy (director of AI at Tesla), Ian Goodfellow (inventor of GAN’s), Chris Olah (co-creator of DeepDream, a great researcher that has no ML degree!), Pieter Abbeel (famous roboticist from Berkley), Jeff Dean (the guy behind TensorFlow, MapReduce, etc.), Francois Chollet (creator of Keras), Soumith Chintala (co-creator of PyTorch), Oriol Vinyals (DeepMind, the guy behind AlphaStar, AlphaFold, etc.), Demis Hassabis (CEO of DeepMind), Ilya Sutskever (one of the key persons in OpenAI).
And here are some AI companies you should probably follow:
DeepMind, OpenAI, Facebook AI, Google AI, Microsoft Research.
Ultimately, I strongly suggest you decide for yourself whom you want to follow. Don’t just copy other people’s networks, build it organically!
Good beginner-friendly blogs
Andrej Karpathy has very nice blogs here and here on Medium.
I especially liked his story “Short Story on AI: A Cognitive Discontinuity”, where he extrapolates the potential of supervised learning into the future — a really thrilling story!
Also, check out Distill pub, which has world-class visualizations of various AI-related topics, and Chris Olah’s blog.
As you can see the logic is simple, track down the “AI influencers” and find whether they have an interesting blog — don’t just follow my advice blindly.
Other great (more advanced) material
The material in this section is something I have not yet fully gone through myself, but I know it’s world-class content. Skim it and see whether some of this works for you (after you finish Coursera/fast.ai courses):
- Ian Goodfellow, Yoshua Bengio, Aaron Courville’s Deep Learning book (it should probably be used more as a reference manual than a book)
- “Andrej Karpathy’s” deep learning course at Stanford (here is the playlist)
- Lex Fridman’s self-driving cars ML lectures
- Talks at the Deep Learning School
- My Discord server (super smart people there), LinkedIn (I post paper summaries and more), Twitter (same as on LinkedIn), YouTube channel (papers, engineering, and beyond), GitHub (various ML projects), Medium blog (as you can see) and monthly AI newsletter. I promise I’ll be only posting AI-related and relevant content. No politics.
Also, a while ago I made a video, based on this blog post:
Final tip: if you are planning to follow along with the deep learning specialization on Coursera as I suggested, consider exploring more about the people appearing in “heroes of deep learning” videos.
I found that YouTube works exceptionally well for these kinds of things, just search for them and usually the best content is the first one to appear.
Where to next?
After you have learned a lot during these 3 months and you became comfortable with the field of machine learning, where should you go next?
My advice is:
Focus on projects, reading and implementing research papers, and repeat! Make sure to share your story along the way! YouTube, GitHub, Medium are all great platforms. Also, create LinkedIn and Twitter profiles if you don’t have them already!
You’re very nicely positioned to help the people who are 1 step behind you. Don’t worry about impressing the best people in the field. Your unique background will be interesting to many people — trust me.
Update, October 2021: I’ve followed my own advice. I made a lot of projects, read a bunch of papers and I was sharing my journey along the way on YouTube, GitHub, Medium, LinkedIn and Twitter. Check out this blog for a complete story on how I landed a job at DeepMind.
If you don’t have any idea for a new project, try solving problems on Kaggle. Kaggle is an awesome data science/machine learning platform, where you can learn a lot by participating in ML competitions, and also earn some money along the way!
Once you’ve completed a couple of your ML projects you can try and monetize them, or find a job on a freelance platform like Upwork.
If you really have an idea you are passionate about — then start a startup!
Or you can apply at some of the best ai companies in the world like Google’s DeepMind, Microsoft Research, OpenAI, FAIR, etc.
With the knowledge you gained during these 3 months and after developing a couple of your own projects you should be heading in a good direction!
Finally, if you don’t know where to start reading papers here are some seminal papers you may find interesting:
(Tip: get used to feeling stupid, you won’t understand many details initially, my YouTube channel may help you get started with reading papers!)
- [CV] A neural algorithm of artistic style (Gatys et al., 2015, introduced NST)
- [NLP] Neural Machine Translation by Jointly Learning to Align and Translate (Bahdanau et. al., 2014, introduced the concept of attention)
- [NLP] Attention Is All You Need (Vaswani et al., 2017, introduced transformers, video)
- [Graph ML] Graph Attention Networks (Veličković et al., 2017, introduced GAT, video)
- [CV] ImageNet classification with deep convolutional neural networks (Krizhevsky et al., 2012, introduced AlexNet)
- [CV] Very deep convolutional networks for large-scale image recognition (Simonyan & Zisserman, 2015, introduced VGG-16)
- [CV] Deep residual networks for image recognition (He et al., 2015, introduced ResNet)
- [CV] Going deeper with convolutions (Szegedy et al., 2014, introduced the Inception network aka GoogLeNet)
- [CV] You Only Look Once: Unified, Real-time Object Detection (Redmon et al., 2015, introduced YOLO)
Also try using Andrej Karpathy’s site he built for making the paper reading process a bit easier: Arxiv Sanity Preserver (I personally don’t use it but see whether you find it useful).
What is my plan?
I will continue to grow in the Microsoft environment, finish my master’s studies with a project in computer vision (I’ll be looking for a cool project idea), do my own ML projects, and I will try to share my experiences along the way here on Medium.
I already started doing a project that involves deep learning for videos, and I am planning to develop a real-time keyword spotter on some embedded system like Raspberry PI, as a way to automate my room!
It’s not easy at all to stick with a plan and go all the way, but I promise you, if you do it you will be grateful. Never give up! That’s one piece of advice I can give you.
If there is something you would like me to write about — write it down in the comment section or DM me. I’d be glad to write more about mathematics & statistics, ML/deep learning, CS/software engineering, landing a job at a big tech company, getting an invitation to prestigious ML camps, etc., anything that could help you!
Also feel free to drop me a message or:
- Connect and reach me on 💡 LinkedIn and Twitter
- Subscribe to my 🔔 YouTube channel for AI-related content️
- Follow me on 📚 Medium and 💻GitHub
- Subscribe to my 📢 monthly AI newsletter and join the 👨👩👧👦 Discord community!
And if you find the content I create useful consider becoming a Patreon!
Much love ❤️
